برای استفاده بهینه از Elasticsearch، لازم است مفاهیم کلیدی آن را به خوبی درک کنیم. این مفاهیم پایهای، اساس طراحی و عملکرد Elasticsearch را تشکیل میدهند:
Index
ایندکس مشابه یک پایگاه داده در دنیای دیتابیسهای سنتی است. هر ایندکس مجموعهای از اسناد مشابه را نگهداری میکند و دارای یک نام منحصربهفرد است. برای مثال، اگر یک وبسایت فروشگاهی دارید، میتوانید یک ایندکس برای محصولات و یک ایندکس جداگانه برای کاربران ایجاد کنید.
Document
سند واحد اصلی داده در Elasticsearch است و به شکل JSON ذخیره میشود. هر سند شامل فیلدها و مقادیر مربوط به آنها است. به طور ساده، هر ردیف در دیتابیس سنتی معادل یک سند در Elasticsearch است.
# مثال JSON سند برای ایندکس محصولات
{
"product_id": 101,
"name": "Laptop",
"price": 2500
}
Field
فیلدها ستونهای یک سند هستند و هر فیلد میتواند نوع داده متفاوتی داشته باشد، مانند متن، عدد، تاریخ یا بولین. برای مثال:
{
"name": "Laptop",
"price": 2500,
"available": true,
"created_at": "2025-09-16"
}
Type
در نسخههای قدیمیتر Elasticsearch (قبل از نسخه 6)، هر ایندکس میتوانست شامل چندین type باشد. هر type شبیه به یک جدول در دیتابیسهای رابطهای بود که اسناد (Documents) با ساختار مشابه را در خود نگه میداشت. اما از نسخه 6 به بعد، استفاده از چندین type در یک ایندکس منسوخ شد و هر ایندکس فقط یک type به نام _doc دارد.
Mapping
Mapping در Elasticsearch مانند Schema در دیتابیسهای رابطهای است. در واقع، mapping مشخص میکند که هر فیلد چه نوع دادهای دارد (مانند عددی، متنی، تاریخ و ...). با استفاده از mapping میتوان رفتار ذخیرهسازی و جستجوی فیلدها را کنترل کرد.
مثال ساده از Mapping در Elasticsearch
PUT products
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "float"
},
"created_at": {
"type": "date"
},
"in_stock": {
"type": "boolean"
}
}
}
}
در این مثال، ایندکسی به نام products ساخته میشود که mapping آن مشخص میکند فیلد name متنی، فیلد price عدد اعشاری، فیلد created_at تاریخ و فیلد in_stock بولین است.
تطبیق Elasticsearch با پایگاهدادههای رابطهای
| Elasticsearch | Relational Database | توضیح |
|---|---|---|
| Index | Database | مجموعهای از اسناد با موضوع مشابه، مانند دیتابیس محصولات یا کاربران. |
| Type (قدیمی) | Table | هر type مشابه یک جدول بود (در نسخههای جدید حذف شده است). |
| Document | Row | هر سند یک رکورد داده را نشان میدهد. |
| Field | Column | هر فیلد یک ویژگی یا ستون داده در یک سند است. |
| Mapping | Schema | ساختار و نوع دادهها را تعریف میکند. |
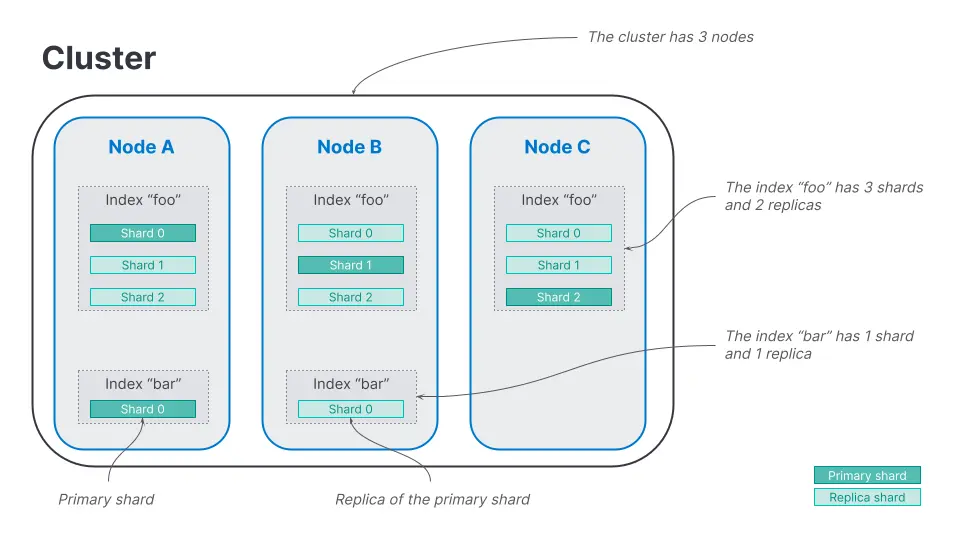
Shard
برای مدیریت دادههای حجیم و افزایش سرعت جستجو، هر ایندکس به بخشهای کوچکتر به نام شارد تقسیم میشود. شاردها میتوانند روی چند نود مختلف قرار بگیرند و بار کاری بین سرورها تقسیم شود. این تقسیمبندی باعث میشود حتی با افزایش حجم داده، سرعت جستجو کاهش نیابد.
| Index | Shards | توضیح |
|---|---|---|
| Products | 5 | این ایندکس به 5 شارد تقسیم شده تا دادهها بین نودها پخش شوند. |
| Users | 3 | این ایندکس به 3 شارد تقسیم شده است. |
Replica
نسخههای کپی شده از شاردها برای افزایش تحمل خطا و دسترسی سریعتر استفاده میشوند. اگر یک نود دچار مشکل شود، replicaها امکان ادامه کار را بدون اختلال فراهم میکنند.
# مثال فرضی
هر شارد اصلی (Primary Shard) = 1
تعداد Replica Shard = 1
تعداد کل شاردها در نودها = 2 شارد برای هر شارد اصلی
Cluster
کلاستر مجموعهای از یک یا چند نود (سرور) است که به صورت یکپارچه با هم کار میکنند. تمام ایندکسها، شاردها و replicaها در یک کلاستر مدیریت میشوند. هر کلاستر یک نام منحصربهفرد دارد و وظیفه آن اطمینان از توزیع دادهها، هماهنگی بین نودها و اجرای جستجوها یا عملیات نوشتن دادهها به صورت مقیاسپذیر و پایدار است.
با درک دقیق موارد بالا میتوانید ساختار دادهها را بهینه کنید و جستجوهای سریع و قابل اعتماد در Elasticsearch داشته باشید.